Fine-tuned LLMs Boost Error Detection in Radiology Reports
AI model trained with synthetic data outperforms GPT-4 in medical proofreading tasks

Fine-tuned large language models (LLMs) greatly enhance error detection in radiology reports, according to a study published in Radiology. Researchers said the findings point to an important role for this technology in medical proofreading.
The accuracy of radiology reports can be compromised by factors like errors in speech recognition software, variability in perceptual and interpretive processes and cognitive biases. These errors can lead to incorrect diagnoses or delayed treatments, making the need for accurate reports urgent.
LLMs like ChatGPT are advanced generative AI models that are trained on vast amounts of text to generate human language. While they offer great potential in proofreading, their application in the medical field, particularly in detecting errors within radiology reports, remains underexplored.
To bridge this gap in knowledge, researchers evaluated fine-tuned LLMs for detecting errors in radiology reports during medical proofreading. A fine-tuned LLM is a pre-trained language model that is further trained on domain-specific data.
“Initially, LLMs are trained on large-scale public data to learn general language patterns and knowledge,” said study senior author Yifan Peng, PhD, from the Department of Population Health Sciences at Weill Cornell Medicine in New York City. “Fine-tuning occurs as the next step, where the model undergoes additional training using smaller, targeted datasets relevant to particular tasks.”
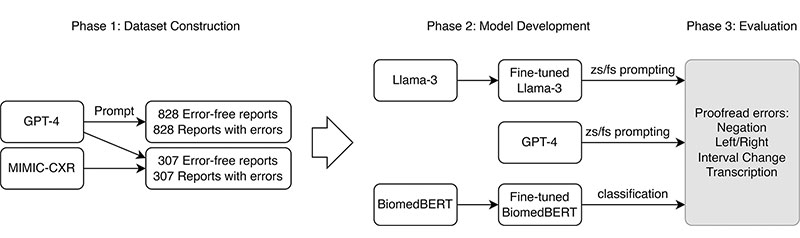
The overall workflow of large language models (LLMs). A dataset was constructed by combining synthetic radiology reports with a small subset of reports from the MIMIC chest radiograph (MIMIC-CXR) database, LLMs such as Llama-3 (Meta AI [31]) and GPT-4 (OpenAI [29]) were refined using zero-shot (zs) or few-shot (fs) prompting strategies, and the models’ performance on the constructed dataset was evaluated.
https://doi.org/10.1148/radiol.242575 ©RSNA 2024
Synthetic Data Boosts Model Accuracy
To test the model, Dr. Peng and colleagues built a dataset with two parts. The first consisted of 1,656 synthetic reports, including 828 error-free reports and 828 reports with errors. The second part comprised 614 reports, including 307 error-free reports from MIMIC-CXR, a large, publicly available database of chest X-rays, and 307 synthetic reports with errors.
The researchers used the synthetic reports to boost the amount of training data and fulfill the data-hungry needs of LLM fine-tuning.
“Synthetic reports can also increase the coverage and diversity, balance out the cases and reduce the annotation costs,” said the study’s first author, Cong Sun, PhD, from Dr. Peng’s lab. “In radiology, or more broadly, the clinical domain, synthetic reports allow safe data-sharing without compromising patient privacy.”
The researchers found that the fine-tuned model outperformed both GPT-4 and BiomedBERT, a natural language processing tool for biomedical research.
“The LLM that was fine-tuned on both MIMIC-CXR and synthetic reports demonstrated strong performance in the error detection tasks,” Dr. Sun said. “It meets our expectations and highlights the potential for developing lightweight, fine-tuned LLM specifically for medical proofreading applications.”
The study provided evidence that LLMs can assist in detecting various types of errors, including transcription errors and left/right errors, which refer to misidentification or misinterpretation of directions or sides in text or images.
The use of synthetic data in AI model building has raised concerns of bias in the data. Dr. Peng and colleagues took steps to minimize this by using diverse and representative samples of real-world data to generate the synthetic data.
However, they acknowledged that synthetic errors may not fully capture the complexity of real-world errors in radiology reports. Future work could include a systematic evaluation of how bias introduced by synthetic errors affects model performance.
The researchers hope to study fine-tuning’s ability to reduce radiologists’ cognitive load and enhance patient care and find out if fine-tuning would degrade the model’s ability to generate reasoning explanations.
“We are excited to keep exploring innovative strategies to enhance the reasoning capabilities of fine-tuned LLMs in medical proofreading tasks,” Dr. Peng said. “Our goal is to develop transparent and understandable models that radiologists can confidently trust and fully embrace.”
For More Information
Access the Radiology article, “Generative Large Language Models Trained for Detecting Errors in Radiology Reports,” and the related editorial, “Will Generative Large Language Models Become Radiologists’ Invaluable Allies?”
Read previous RSNA News stories about medical imaging AI: